
One of our current projects is about training a model that performs crack detection on concrete slabs. The main goal is to optimize the process in production. Cracks on the surface are a major defect in concrete structures. Timely crack detection helps construction companies and concrete product manufacturers to prevent potential losses.
There are various approaches to solving this problem, some of them involve manual inspection and others are based on automatic detection methods. Nowadays, the increased efficiency of modern neural network models and Computer Vision technologies makes an automatic approach out of competition compared to the manual one, allowing to optimize the process without losing any accuracy.
Crack detection is the semantic segmentation problem. Semantic segmentation refers to the process of linking each pixel in an image to a class label. In this case, we need to find all pixels of cracks on the photo of a concrete structure.

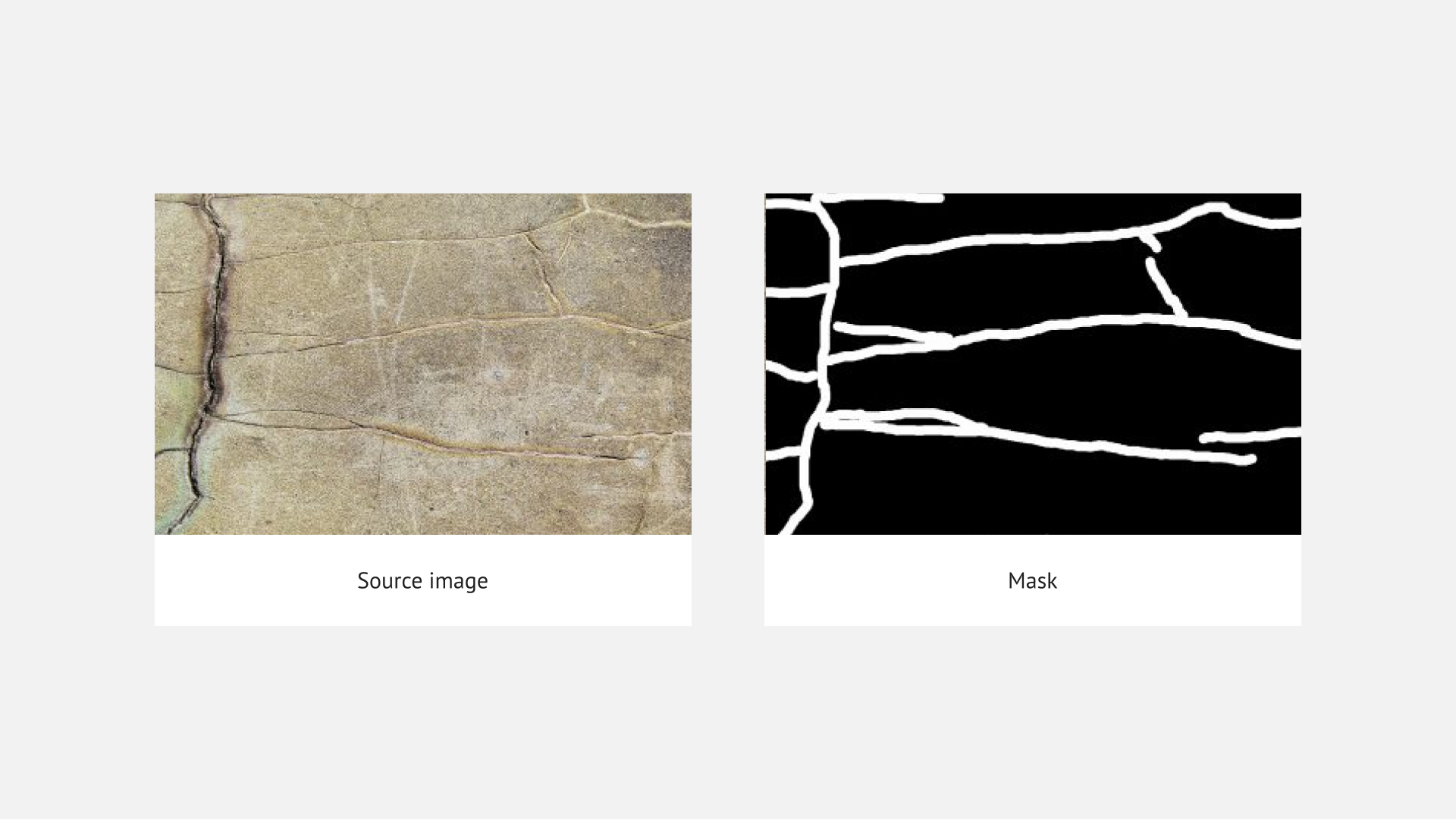
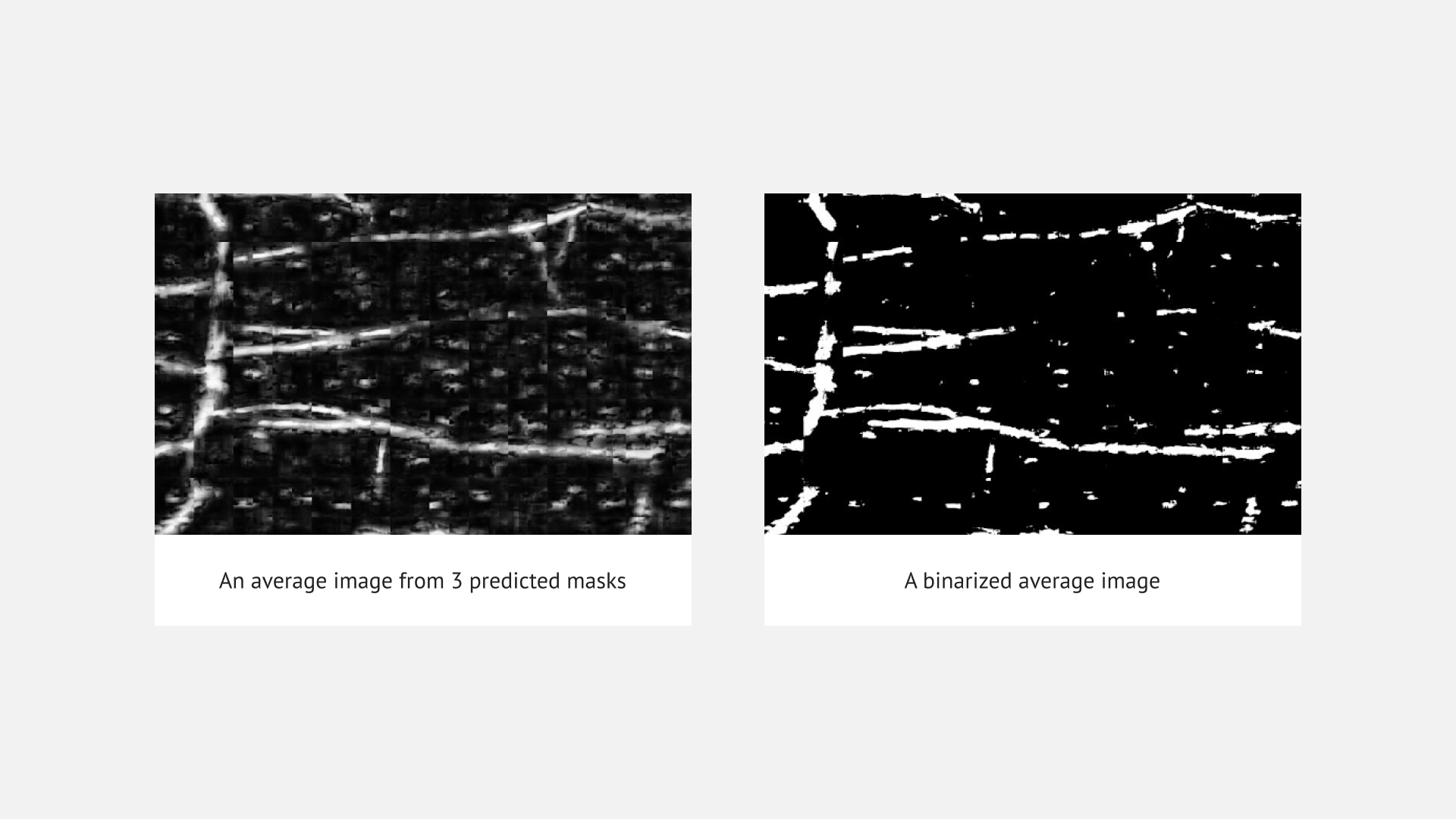
The metric to evaluate our model was the Sørensen–Dice coefficient. After training, the value of this metric is 95% on the train set and 93% on the validation set.
Figures 2-4 show an example of prediction for the input image (figure 1).
Business value
The solution helped our client to automate the process of concrete cracks detection in production and almost eliminate the need for human participation in it. This means that our solution can save a company from at least 20 human hours a week (or around $20,000/year) for each production line.
In the future, it is planned to configure the model for rust recognition and build a predictive model for flaws search.


